Challenge
Start of topic | Skip to actions
Participating Team
- Short team name: REDUX, Database Research Group, MSR
- Participant names: Roger S. Barga and Luciano A. Digiampietri
- Project URL: http://research.microsoft.com/~barga/
- Project Overview: The goal of our project is to capture result provenance automatically as the workflow (experiment) is executing, and to introduce techniques to query and manage this provenance data efficiently. We introduce a layered model for experiment result provenance, which allows navigation from an abstract model of the experiment to instance data collected during a specific experiment run. We identify modest extensions to enable a workflow management system to capture provenance data, along with techniques to efficiently store this provenance data in a relational database management system. Our current implementation is based on the Windows Workflow Foundation and SQL Server 8.0.
- Provenance-specific Overview: (see below).
- Relevant Publications:
- RS Barga, LA Digiampietri, Automatic Generation of Workflow Provenance, In the Proceedings of IPAW06.
- RS Barga, LA Digiampietri, Automatic Capture and Efficient Storage of eScience Experiment Provenance, in submission.
Workflow Representation
Our workflows are represented in three abstraction layers: AbstractWorkflow, WorkflowModel and ExecutableWorkflow. In AbstractWorkflow layer, we use two main concepts: WorkflowType and ActivityType. WorkflowType contains the general types of the workflow that can be represented (for example, sequential workflow, state machine workflow and event drive workflow). ActivityType contains the general types of activities (command line activities, Web services, C# Code Activities, etc) and a set of properties assigned to each activity (for example, a Web service activity has a property called Proxy). In our Provenance Challenge workflow examples, we have only sequential workflows using command line activities. The AbstractWorkflow layer contains the type of workflow that is being stored and the links among ActivityTypes. Figure 1 presents the graphical representation of the first workflow example, using Windows Workflow Foundation (WinFX). In our model, we do not need to store activities that represent execution constructions (such as parallel activities or sequence activities). These constructors can be automatically implied from our links.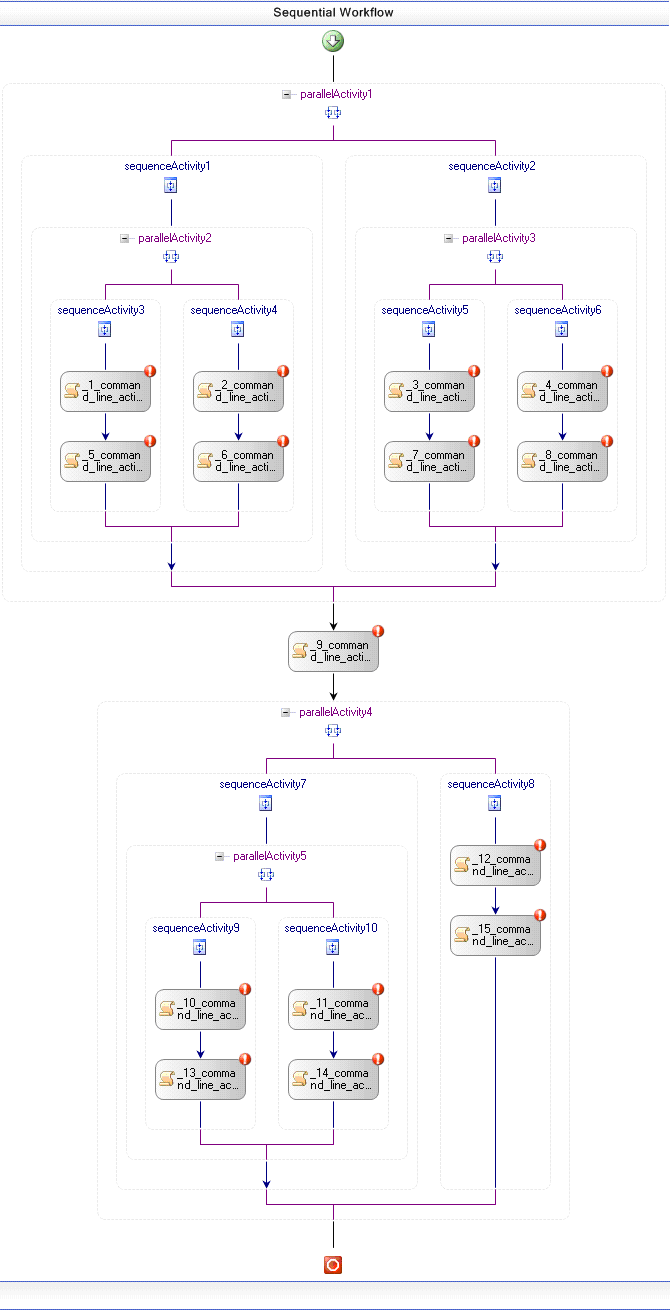
Figure 1 Abstract Workflow using Windows Workflow Foundation graphic representation
Figure 2 presents a simpler way to visualize the information of the Abstract Workflow layer.
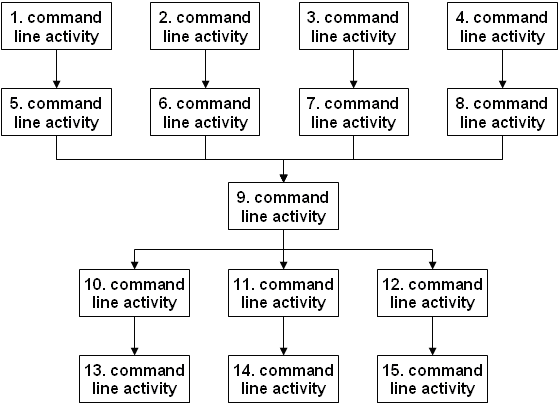
Figure 2 Simpler representation of Abstract Workflow information
Figure 3 presents the part of our data model that stores information about Abstract Workflows and the relationships among keys and foreign keys. It is important to note that inside an AbstractWorkflow, activities can be linked by Port (data channels) or Links. The difference is that the linkage using Links is between two activities and the linkage using Ports is between two activities ports. In the graphical representation from Windows Workflow Foundation, you can see only links among Activities, but you have implicit links among information (ports) using shared variables. Our data model allows both kinds of linkage.
The Tables DataType, Property and Value are shared in our model (they are used by several tables in all the layers of our provenance model, including the provenance representation) to allow information reuse. Table AbstractWorkflowAnnotation_Property_Value contains the annotations made by users about the Abstract Workflows.
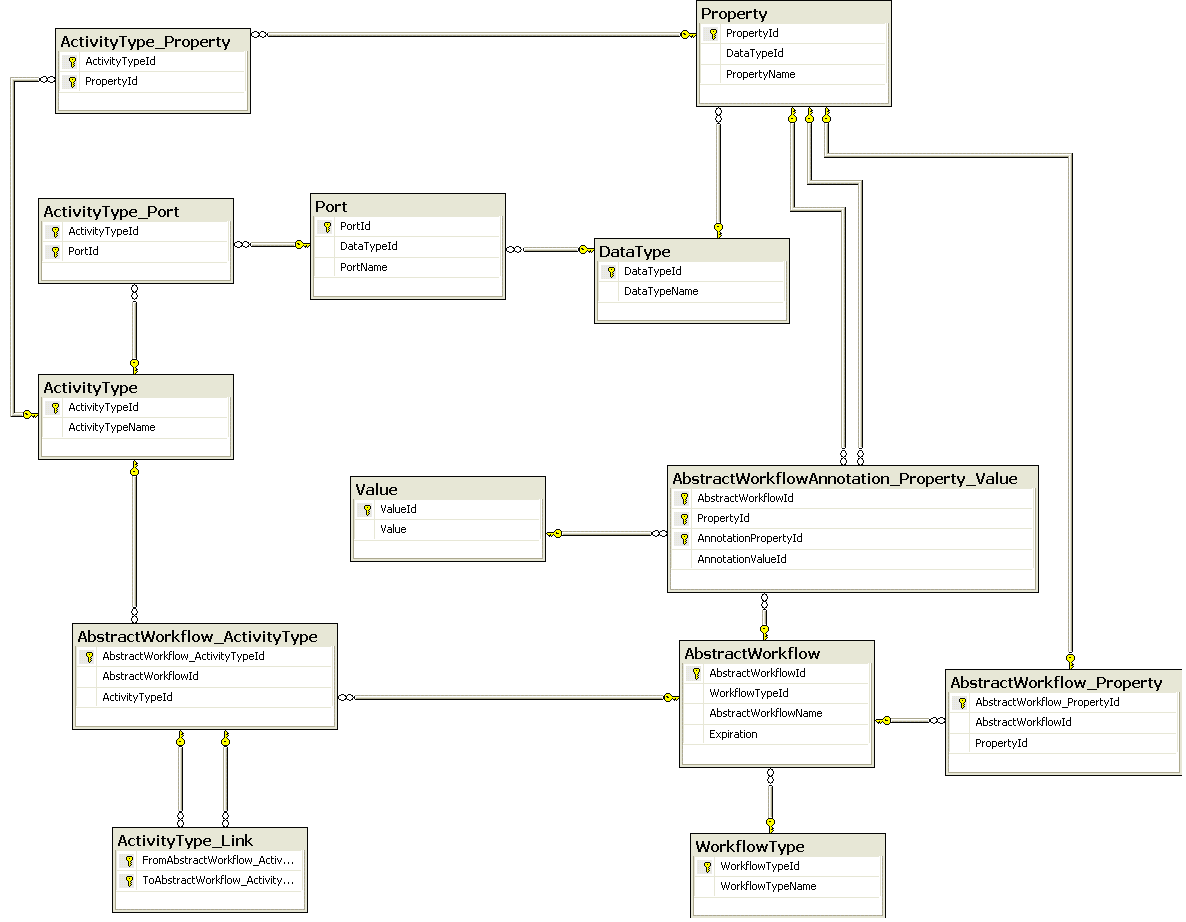
Figure 3 The part of our data model that contains information about Abstract Workflows
The WorkflowModel layer contains information about the activities (instances). In this layer, we also specify the Ports of each activity and the linkage among the Ports. We also assign properties (or parameters) to the activities. This layer is responsible for details about the general structure of the workflow and its activities. The unique information that is not provided in this layer is: input data and values of the input parameters (in this layer we specify the parameters of each activity, using the tables Property and Activity_Property, but we will fill the value of the parameters in the next layer, linking the data from table Value using the table ExecutableActivity_Property_Value). Figure 4 shows the graphical representation of the example workflow using the Windows Workflow Foundation. Remember the bindings among the ports are implicit. Figure 5 shows an explicit representation of our Ports linkage.
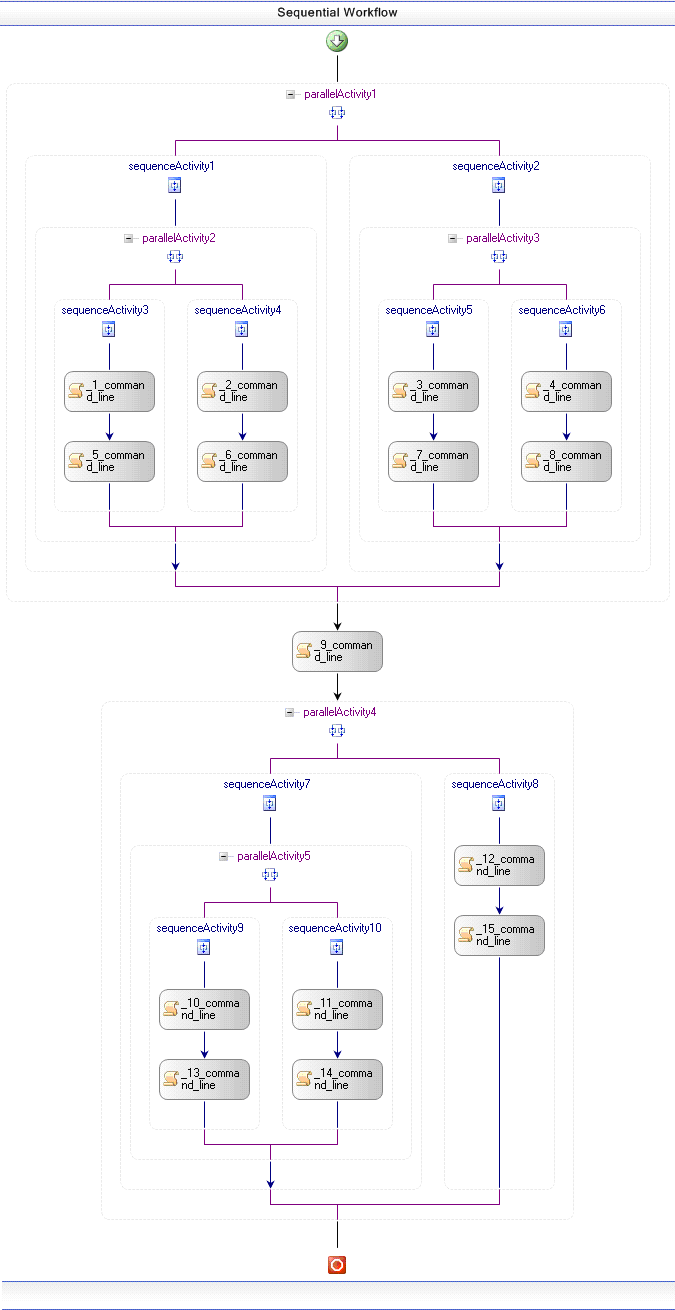
Figure 4 - Workflow Model using Windows Workflow Foundation graphic representation
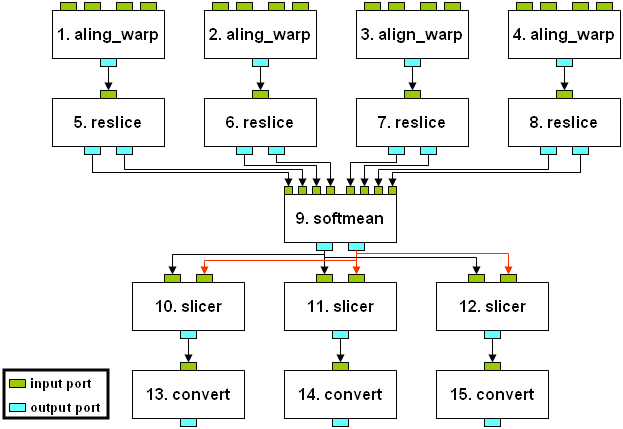
Figure 5 Explicit port linkage for Workflow Model information
All Ports (inputs and outputs) are of some DataType. We colored selected arrows in Figure 5 only to facilitate the understanding of the figure. The input ports that do not receive information from an output port are called _Input Data Port_ and must be filled in before the execution of the workflow). This kind of information and the values of the input parameters are specified in the next layer (ExecutableWorkflow).
Figure 6 shows the part of our data model that corresponds to WorkflowModel layer.
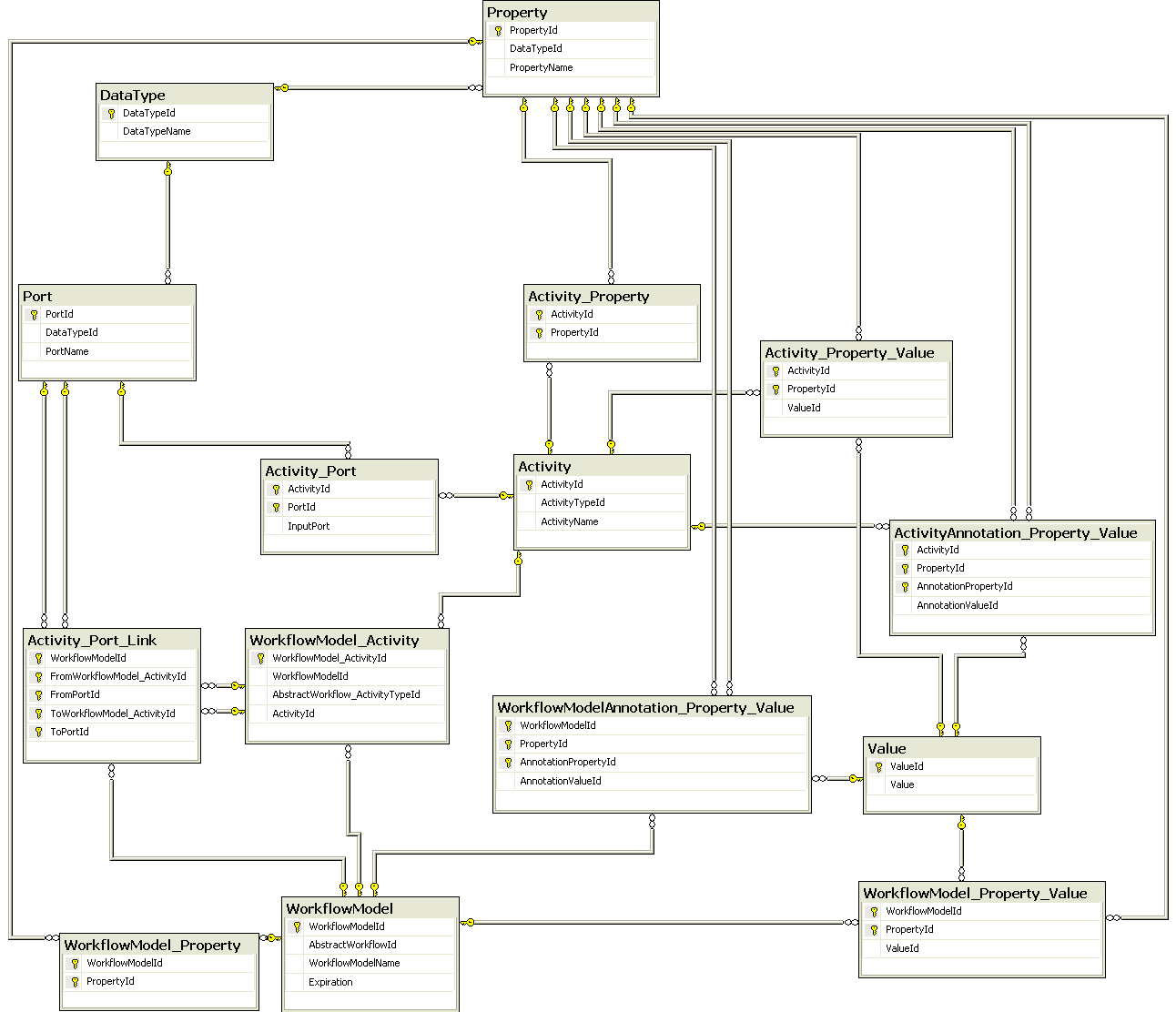
Figure 6 The part of our data model that contains information about Workflow Models
The ExecutableWorkflow layer contains details on the parameters and input data of a Workflow Model. The Workflows in the Executable Workflow layer are ready to be executed. In this layer, the user can also insert annotations about the input data or about the executable workflow. The main concepts here are ExecutableWorkflow that extends a WorkflowModel (and fills in its input data and input parameters) and ExecutableActivities that correspond to the Activities from WorkflowModel plus the set of input parameters (assigned as properties and values).
Table InputPort_Property_Value contains information about the input data (data that is assigned to input ports). Table InputDataAnnotation_Property_Value contains annotations about input data. Table ExecutableActivity_Property_Value assigns values to activity properties.
Figure 7 shows the tables related with Executable Workflows and the relationships among keys and foreign keys.
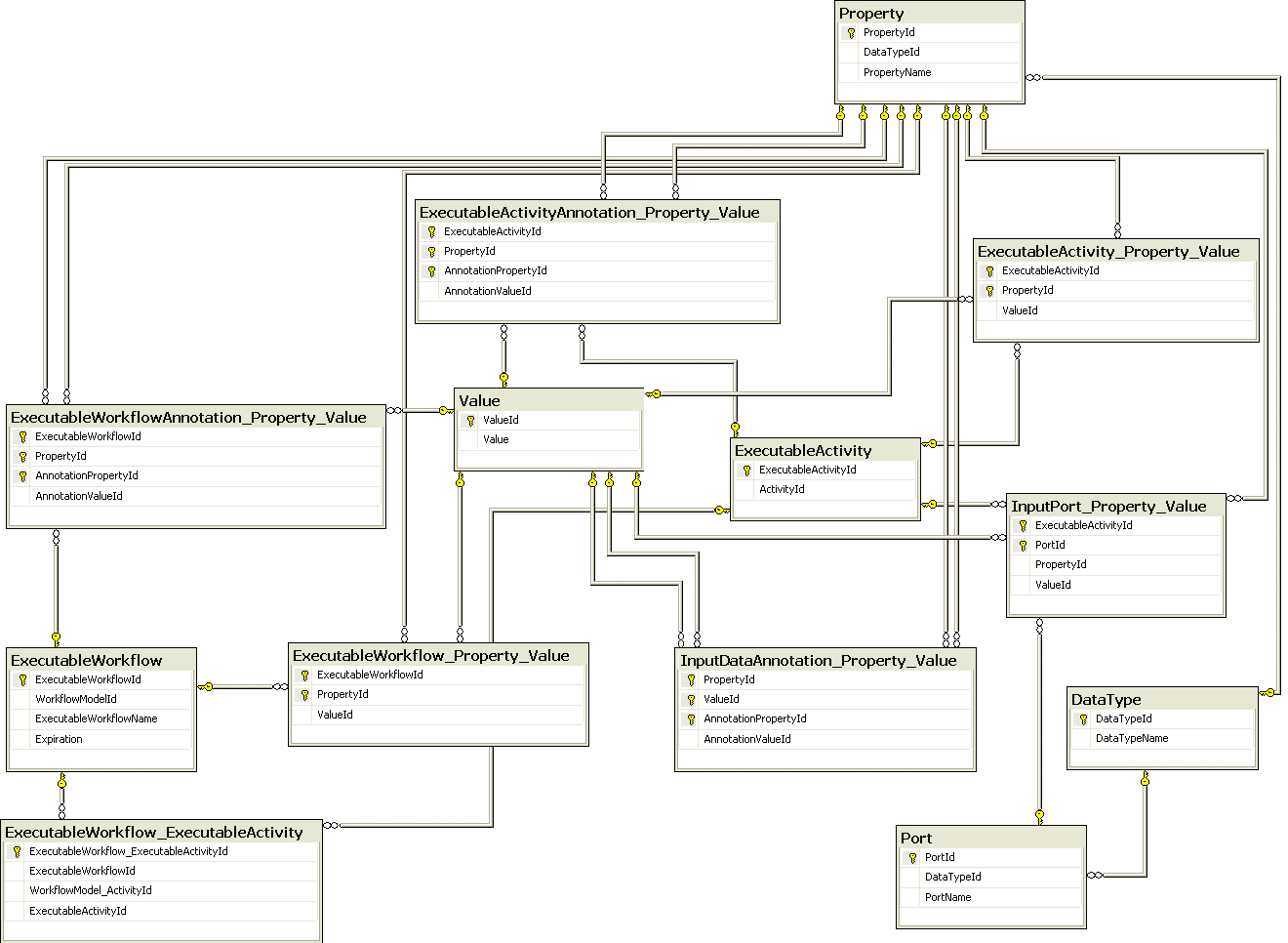
Figure 7 The part of our data model that contains information about Executable Workflows
The next layer of our data model contains information about the execution of workflows, and we describe this layer in the following section.
Provenance Trace
The Provenance Trace has two main concepts: Execution and Event. Execution corresponds to the data about a complete execution of an Executable Workflow. An execution is composed of Events. The model allows the user to store the Event Types that are interesting to his application. Examples of basic event types are: activity start, data production and activity end. Events are related to the execution of some Executable Activity. The table Event_Property_Value contains the properties and values assigned to each Event. This information also includes produced data. The user can annotate events or produced data using the table EventAnnotation_Property_Value. Other information that is stored in the system is about date and time. Each event has a timestamp, and each execution has a start and an end time. Executions also have an Expiration field that contains the date in which the execution (and its events) can be deleted (AbstractWorkflows, WorkflowModels and ExecutableWorkflows also have this field). Events can be shared for more than one execution and the workflow engine can take advantage of this to avoid executing the same executable activity more than once (that is, the same activity with the same parameters); in other words, our model will allow smart re-runs of the workflow. Figure 8 shows the tables related to the Provenance Trace.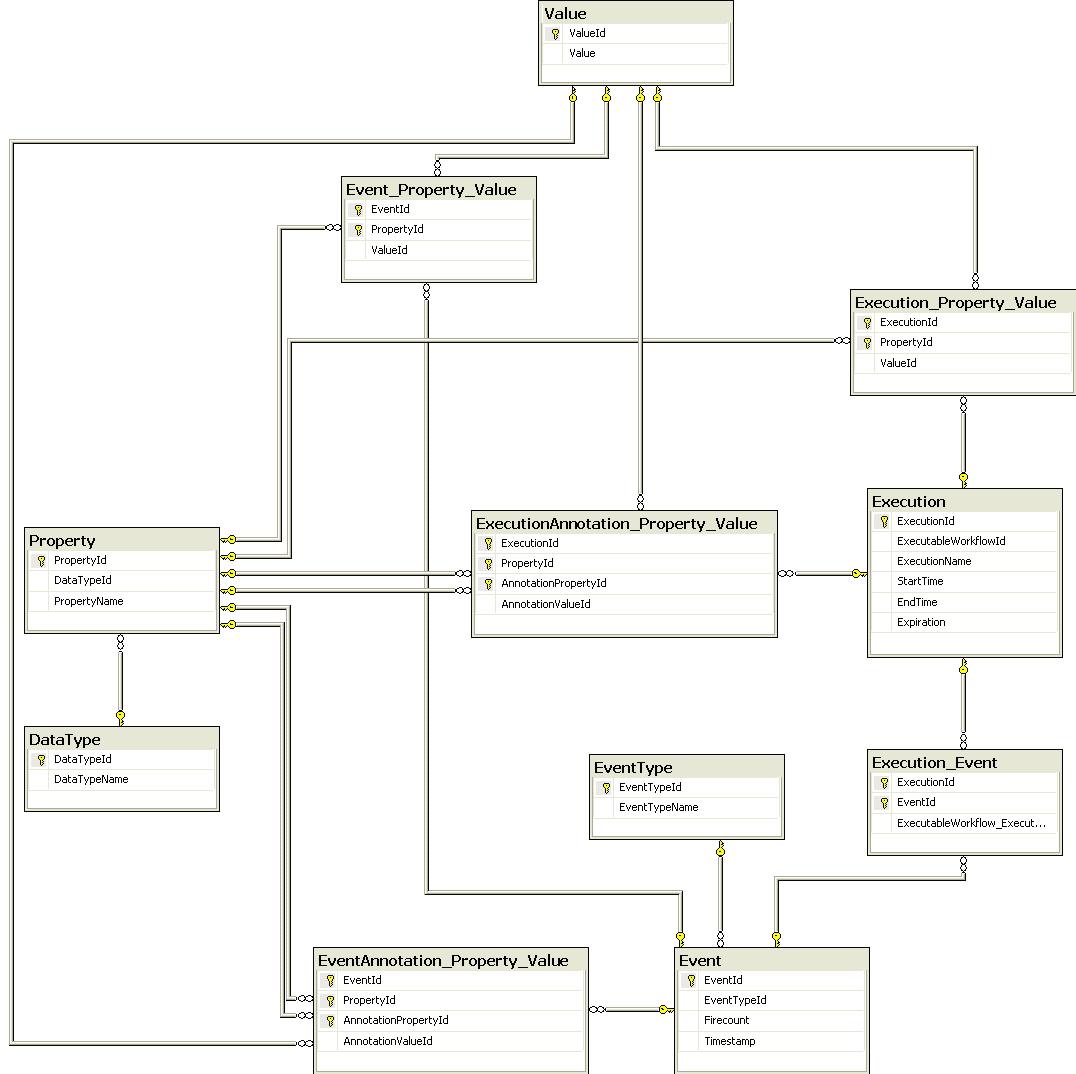
Figure 8 The part of our data model that contains information about Executable Workflows
Provenance Queries Matrix
| Teams | Queries | ||||||||||
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | |||
| REDUX team |  | | | | | | | | | ||
Provenance Queries
A premise of our project is that a relational database will serve a satisfactory store for provenance data, and that we can leverage the available storage manager, indexing and query processing to implement efficient storage and querying techniques. In this section, we present the SQL queries that answer the provenance queries defined in the Challenge. We have implemented a simple graphic tool to present results when we need to recursively search the model, specifically provenance queries 2, 3 and 6. The results of the remaining queries will be presented using a screenshot of the SQL Server version 8.1. Find the process that led to Atlas X Graphic / everything that caused Atlas X Graphic to be as it is. This should tell us the new brain images from which the averaged atlas was generated, the warping performed etc.
The result in our model is an ExecutableWorkflow_ExecutableActivityId (executable activity that produced the data). Having this result, we can use it to show all the process (see queries 2, 3 and 6). This SQL query returns the ExecutableWorkflowId (process), ExecutionId (id of the specific execution of the process), EventId (event where the data was produced) and ExecutableWorkflow_ExecutableActivityId (activity that produced the data) of the processes that generated the Atlas X Graphic.
This SQL query returns the ExecutableWorkflowId (process), ExecutionId (id of the specific execution of the process), EventId (event where the data was produced) and ExecutableWorkflow_ExecutableActivityId (activity that produced the data) of the processes that generated the Atlas X Graphic.

Figure 9 - Query 1 result.
2. Find the process that led to Atlas X Graphic, excluding everything prior to the averaging of images with softmean.
Starting from the activity that produced the Atlas X graphic (as you can see in the previous query, the ExecutableWorkflow_ExecutableActivityId of this activity is 13) we can use our graphic tool to present all the process that produced the data. Since we want to exclude everything prior to the averaging of images with softmean, we need to insert a query in the Exclude box, which will find the activities to be excluded. This query is: Figure 10 shows the result of this execution. The check box Reverse is checked because we are starting from the end of the process (activity 13 [convert]) and came back until we reach softmean.
Figure 10 shows the result of this execution. The check box Reverse is checked because we are starting from the end of the process (activity 13 [convert]) and came back until we reach softmean.
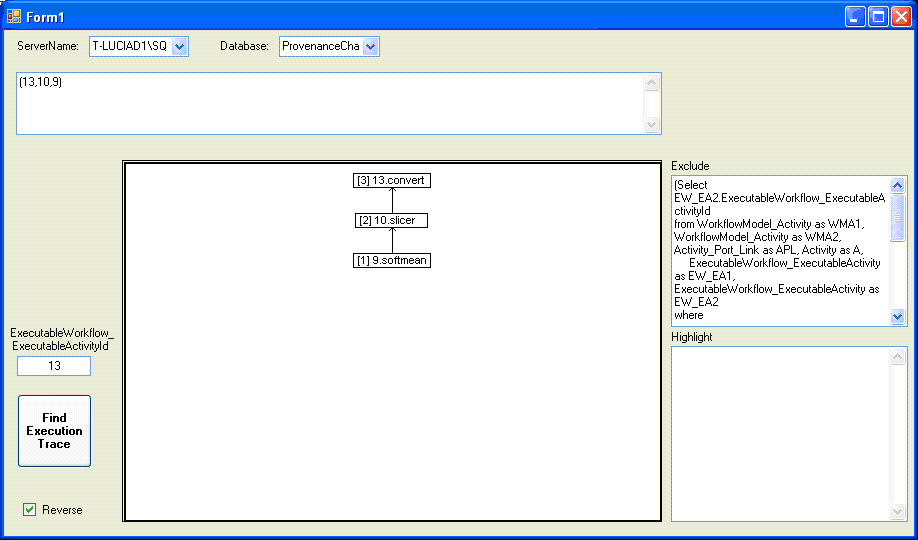
Figure 10 - Execution of query 2
3. Find the Stage 3, 4 and 5 details of the process that led to Atlas X Graphic.
The result is the activities with the set of parameters. Our system presents the stage of the process between [ ]. Here, we only ask for the system to generate the reverse pathway of the execution starting from convert (activity 13) that is the activity that generated the Atlas X Graphic (see query 1). Figure 11 shows the full execution graph (stating from 13.convert). We highlight manually the activities that the system identified as stages 3 (9.softmean), 4 (10.slicer), and 5 (13.convert).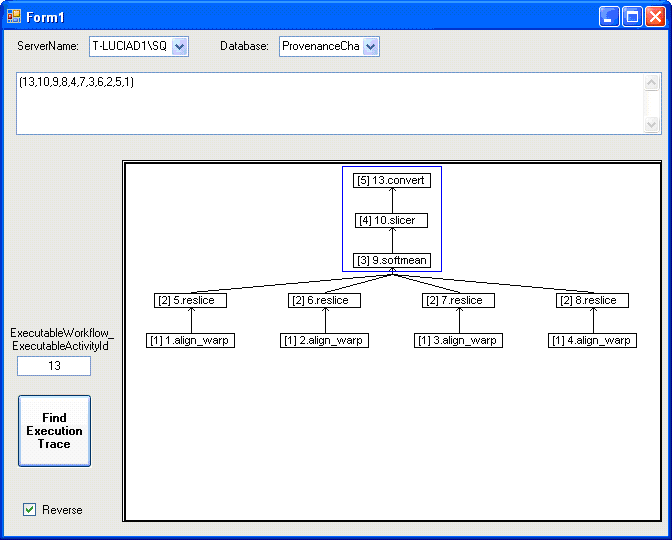
Figure 11 - Execution of query 3
4. Find all invocations of procedure align_warp using a twelfth order nonlinear 1365 parameter model (see model menu describing possible values of parameter "-m 12" of align_warp) that ran on a Monday.
The result is a set of ExecutableActivityIds. Since we have execution time we can ask about Monday. The twelfth order nonlinear 1365 parameter is represented in our system as a property of the ExecutableActivity. This SELECT command returns the activities that were started on a Monday (can be easily update to return activities that started and ended in a Monday or in the same Monday, etc). Figure 12 shows the results of this query. This result shows, basically, that all the align_warp (ExecutableActivities from 1 to 4) were executed (in both executions) used the desired parameter (-m 12).
This SELECT command returns the activities that were started on a Monday (can be easily update to return activities that started and ended in a Monday or in the same Monday, etc). Figure 12 shows the results of this query. This result shows, basically, that all the align_warp (ExecutableActivities from 1 to 4) were executed (in both executions) used the desired parameter (-m 12).
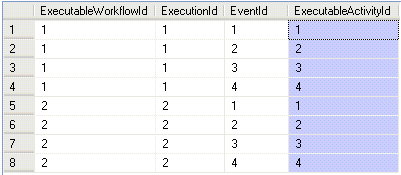
Figure 12 Query 4 results
5. Find all Atlas Graphic images outputted from workflows where at least one of the input Anatomy Headers had an entry global maximum=4095. The contents of a header file can be extracted as text using the scanheader AIR utility.
The result is a set of Properties and Values that satisfy the query constraints. In our model, the textual information about the headers is stored as annotations in this specific case, Input Data _Annotations_.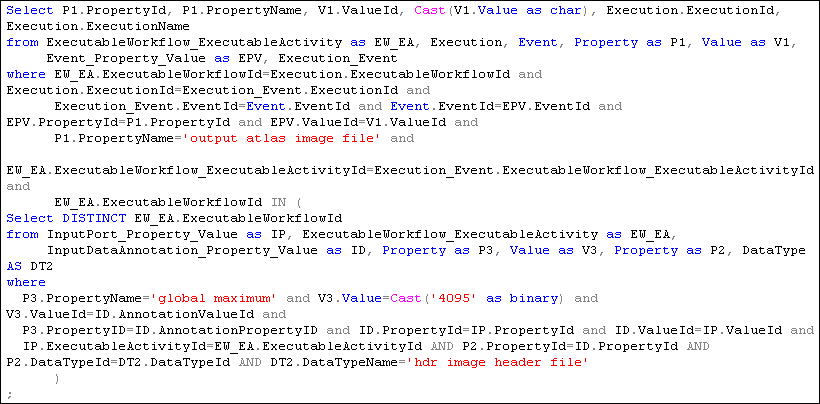 Figure 13 shows the result of this query. It is interesting to note that the same data was generated by the both workflows. It means that the workflows are sharing the data (inside our model), so we have only one copy of the data in our system.
Figure 13 shows the result of this query. It is interesting to note that the same data was generated by the both workflows. It means that the workflows are sharing the data (inside our model), so we have only one copy of the data in our system.

Figure 13 - Query 5 results
6. Find all output averaged images of softmean (average) procedures, where the warped images taken as input were align_warped using a twelfth order nonlinear 1365 parameter model, i.e. "where softmean was preceded in the workflow, directly or indirectly, by an align_warp procedure with argument -m 12."
Here, we will have to answer the question about order. It can be done since all our activities are linked. Since it is a recursive query (that has to navigate among the workflows) it will be solved by our Query Tool, but first we wish to show an interesting SQL query that partially answer the desired query: Here the SQL query only find the data produce by softmean when it is directly preceded by an align_warp or preceded by some activity directly preceded by an align_warp (it is a recursive search, easily implemented in our query tool [max number of iterations is limited by the longest path of an executable workflow; later, we will present a solution using our graphical program]).
Figure 14 presents the result of this query. There is only one (distinct) result.
Here the SQL query only find the data produce by softmean when it is directly preceded by an align_warp or preceded by some activity directly preceded by an align_warp (it is a recursive search, easily implemented in our query tool [max number of iterations is limited by the longest path of an executable workflow; later, we will present a solution using our graphical program]).
Figure 14 presents the result of this query. There is only one (distinct) result.

Figure 14 - Query 6 result
Using our graphic program we can, for example, highlight the align_warp that precede the softmean. Figure 7 shows the results of our program where we inserted the softmean id in the ExecutableWorkflow_ExecutableActivityId box (id=9) and we inserted a query to identify the align_warp activities in the Highlight box:
 The check box Reverse is checked because we will follow the reverse pathway of the execution (from the end ![_softmean_] to the start).
The check box Reverse is checked because we will follow the reverse pathway of the execution (from the end ![_softmean_] to the start).
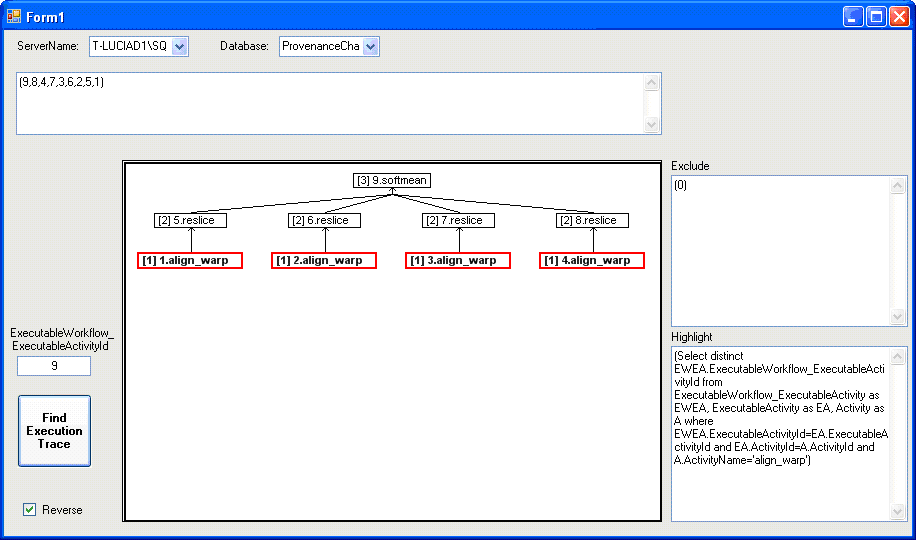
Figure 15 - align_warps that precede softmean
Other possibility is to insert the id of the align_warp in the ExecutableWorkflow_ExecutableActivityId box (ids: 1, 2, 3 or 4) and ask for the system to highlight the softmean activities (if found). The check box Reverse is unchecked because we will follow the execution pathway. Figure 16 shows the screenshot of this execution.
Figure 16 softmean that was preceded by 1. aling_warp
7. A user has run the workflow twice, in the second instance replacing each procedures (convert) in the final stage with two procedures: pgmtoppm, then pnmtojpeg. Find the differences between the two workflow runs. The exact level of detail in the difference that is detected by a system is up to each participant.
Our layered model allows the detection of differences in several ways. First, we can detect differences in the structure of different workflow models (experiment designs). In our model, the workflow general structure is referred to as Abstract Workflow. The Abstract Workflow contains information about the Types of the activities in the workflow, the Links between individual activities, and general information about the Workflow Type. In this example we have a Sequential Workflow; others possible workflows types include State Machine Workflow and Event Driven Workflow. Since the problem presented by the Provenance Challenge does not use a specific technology to specify the activities (Web services, EXE files, etc), we consider that all activities belong to the Activity Type: command line activity. Figure 17 presents the graphical representation of the abstract workflows of the 2 sample workflows. The concept Activity Type is useful to aggregate activities with same general characteristics. For example, all Web service activities have the property/parameter called Proxy.| Workflow 1 | 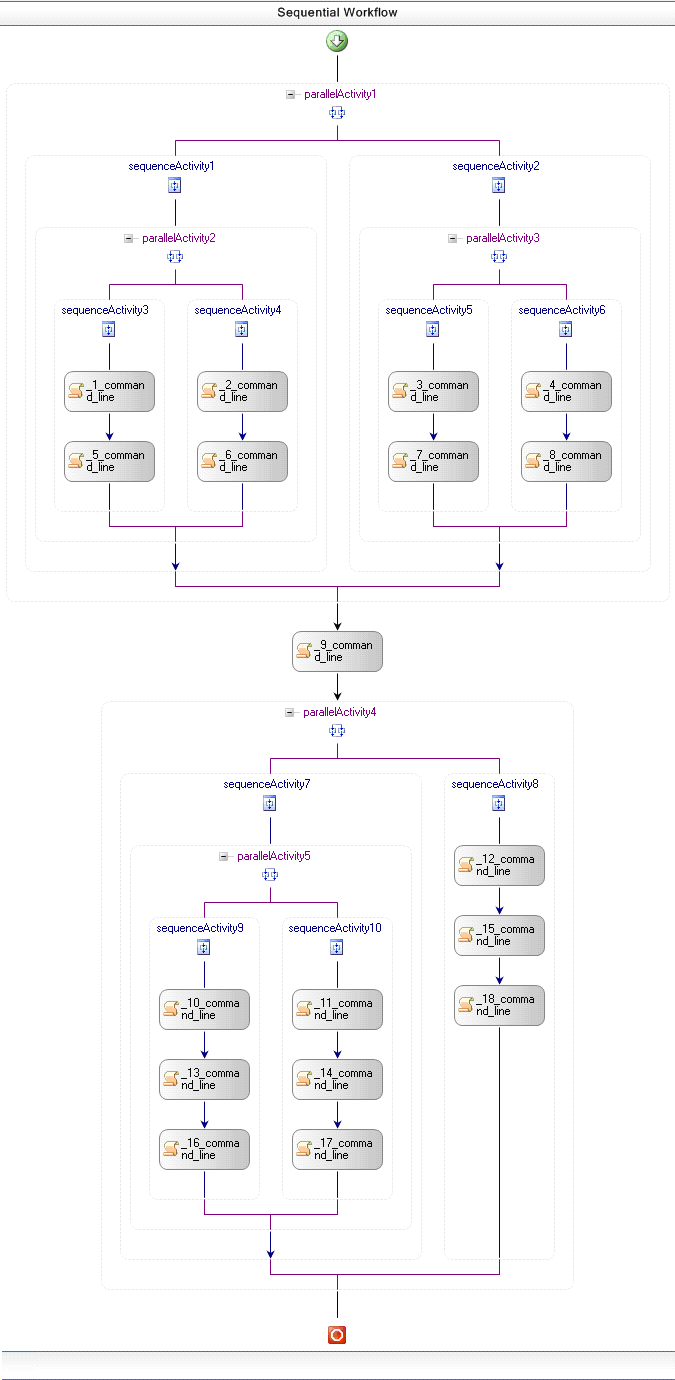 Workflow 2 Workflow 2 |
Figure 17 - Abstract Workflows
In the next level of our model, Workflow Model captures information about the instances of the activities, and the links among the ports (or activities interfaces). At this layer, our model allows provenance queries to question, for example, what activities from Workflow 2 are not included in Workflow 1:
Activities that are used by the second workflow but are not used by the first:
 The result of this query is presented in Figure 18.
The result of this query is presented in Figure 18.
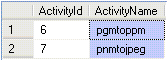
Figure 18 - Activities from workflow 2 that are not present in workflow 1
You can also make more detailed queries, for example, about the links of the ports of these activities.
The next level of our model, Executable Workflow, contains the parameters and input data of all activities. Here, the workflow is ready to be executed. If two workflows are different only in the input parameters, in our model they will use the same Workflow Model and there will be differences only in the Executable Workflow level.
The two workflow samples are very similar in this layer, because they use the same input date.
The last layer is the Runtime Workflow (Execution Provenance) which contains information about the execution of the workflow (produced data, timestamps, activities invoked, etc). Here, the model allows queries about produced data, data flow (as showed in queries 2 and 3), date/time, etc.
One example of query that shows the difference between the two workflows, at this level, is:
What is the data produced by the second workflow that was not produced by the first?
 Figure 19 shows the data produced by workflow 2 that was not produced by workflow 1.
Figure 19 shows the data produced by workflow 2 that was not produced by workflow 1.
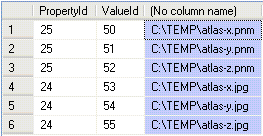
Figure 19 - Data produced only by workflow 2
One important thing to observe here is that even with this great amount of differences we highlighted, the two workflows are sharing more than 99% of the provenance data (considering the space occupied by the data) and 45.87% of the database tuples (about 45,87% of the database tuples are used by both workflows). Table 2 summarizes this information.

Table 2 - Number of tuples and space occupied by the workflows
8. A user has annotated some anatomy images with a key-value pair center=UChicago. Find the outputs of align_warp where the inputs are annotated with center=UChicago.
These annotations are stored in our model as InputDataAnnotation. We annotated the images 1 and 2 with: _Property_=center and _Value_=UChicago to allow this query.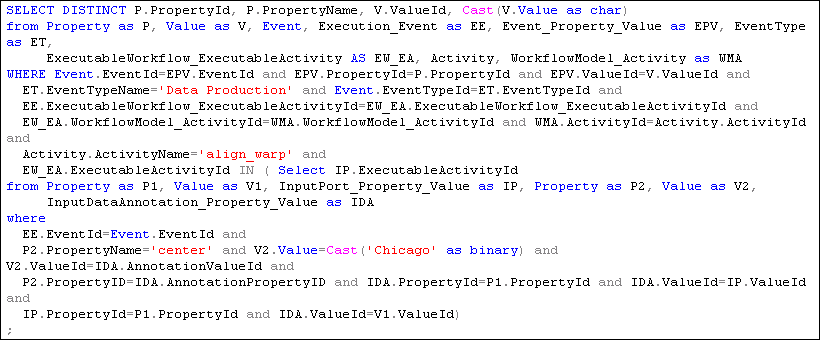 Figure 20 shows the results of this query.
Figure 20 shows the results of this query.

Figure 20 - Query 8 results
9. A user has annotated some atlas graphics with key-value pair where the key is studyModality. Find all the graphical atlas sets that have metadata annotation studyModality with values speech, visual or audio, and return all other annotations to these files.
The query will return all annotations of the desired data. In our example, we annotated the output atlas image only with the property studyModality and value visual. Figure 21 presents the results of this query.
Figure 21 presents the results of this query.

Figure 21 - Query 9 results (all annotations)
The following query will present all annotations but studyModality. In our example, it will not return anything (because we only have the studyModality annotation).

Suggested Wokflow Variants
One of the most interesting aspects of the REDUX project is that we introduce methods to efficiently store provenance data. We suggest the following workflows variants as example to that highlight the ability of provenance systems to reuse provenance data include the following:- The experiment repeats two executions of the same Executable Workflow (same model and same input data): the model allows the reuse of all information, including produced data, so the workflow engine should only execute the activities that are assigned as non-cacheable (and the activities in the workflow preceded by these activities);
- Two different Executable Workflows, with different input data and activity parameters, but with the same Workflow Model (same structure and activities): our provenance system will record differences in the workflow only in the Executable Workflow layer. Moreover, differences will only be recorded in the Executable Workflow layer if some Executable Activity (activity and parameters) are used by these two workflows, so, inside our model, they will share this information.
Suggested Queries
Categorization of queries
In our system we have two broad categories: the first is based in the way that the query must be processed, while the second is based on the layers of the model. Categorization about the way in which a query must be processed: recursive queries (must follow the execution, in the order of tasks: give-me the second activity executed in a given workflow) or static queries (is there is a softmean activity in a given workflow?). Categorization about the layers of the model:- Abstract Workflow: queries about the structure of the workflow (experiment);
- Workflow Model: queries about the activities bound to the experiment and the links between activities;
- Executable Workflow: queries about the parameters and input data;
- Runtime Workflow (execution data): queries about the execution and events (time in which some events occurred, data produced, etc).
Live systems
Further Comments
Both, our provenance model and associated data model, were specified to facilitate the sharing of provenance data in all layers. Tables 3 and 4 show, respectively, the number of tuples and the space used to store the provenance from the two workflow examples. In our model, all information, including input data, produced data and annotations are stored in a relational database. The two proposed workflows have differences, in our model, in all layers: differences in the structure (Abstract Workflow), in the activities (Workflow Model), in the parameters (Executable Workflow) and in the produced data (Runtime Workflow: execution and events). Even with the great amount of differences, they share more 45% of the tuples in our database and, when considering the space used, they share more than 99% of the space.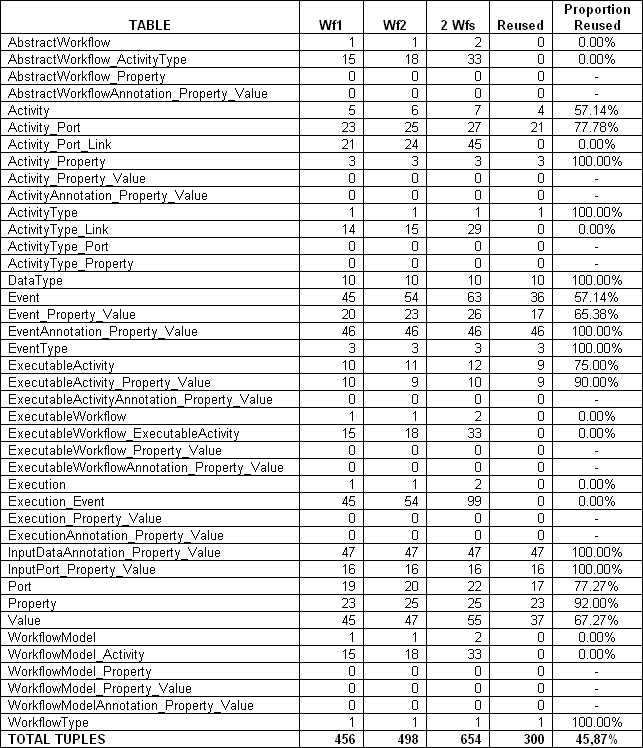
Table 3 Number of tuples in our database
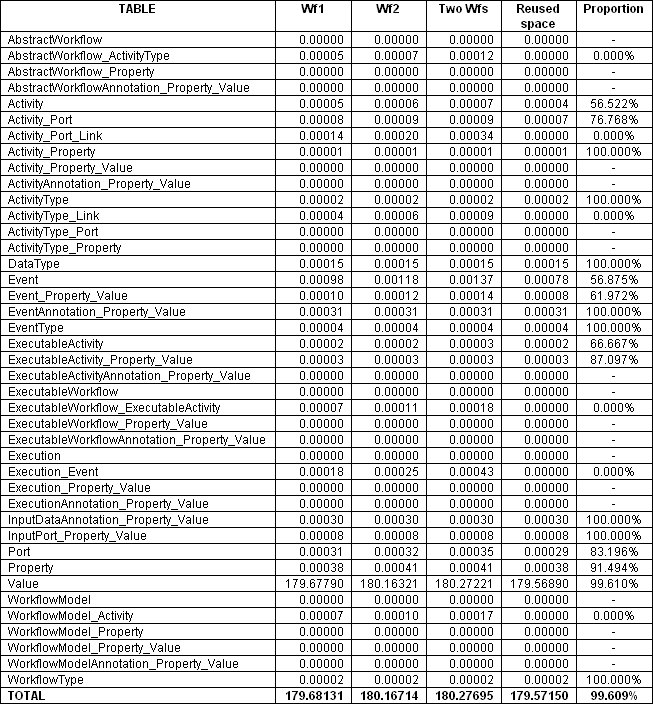
Table 4 Space used to store the workflows in our database
Conclusions
Provide here your conclusions on the challenge, and issues that you like to see discussed at a face to face meeting.to top
Edit | Attach image or document | Printable version | Raw text | More topic actions
Revisions: | r1.6 | > | r1.5 | > | r1.4 | Total page history | Backlinks
Revisions: | r1.6 | > | r1.5 | > | r1.4 | Total page history | Backlinks