Challenge
Start of topic | Skip to actions
Provenance Challenge Template
Participating Team
- Short team name: myGrid
- Participant names: Jun Zhao, Carole Goble and Daniele Turi
- Project URL: http://www.mygrid.org.uk
- Project Overview: myGrid is a pilot e-Science project in the U.K. It provides a collection of middleware services to support bioinformaticians to perform in silico experiments. Taverna is a workflow composition and execution workbench. It also integrates the capability of semantic service discovery through the Feta plugin. Data and their provenance are automatically collected during workflow runs.
- Provenance-specific Overview: applying the semantic web technologies to represent and query provenance information.
- Relevant Publications:
- Jun Zhao, Carole Goble and Robert Stevens. An Identity Crisis in The Life Sciences.In International Provnenace and Annotation Workshops, May 2006
- Jun Zhao, Chris Wroe, Carole Goble, Robert Stevens, Dennis Quan and Mark Greenwood. Using Semantic Web Technologies for Representing e-Science Provenance. In the Third International Semantic Web Conference, Hiroshima, Japan, November 7 - 11, 2004
Workflow Representation
Our workflow is represented using the Scufl language.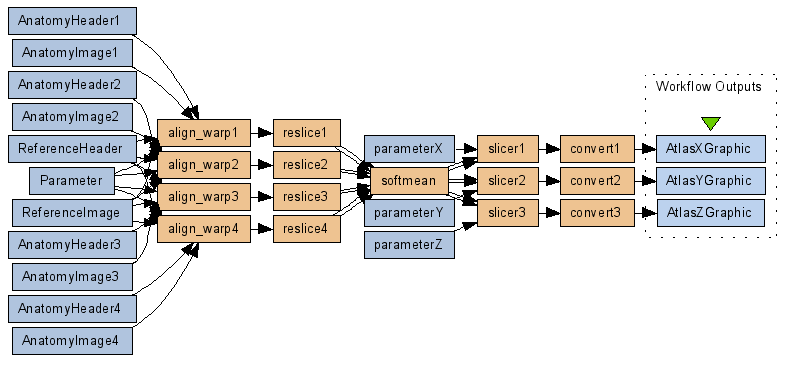
Figure 1 The Scufl Workflow for the challenge
Provenance Trace
Our provenance is recorded as RDF (Resource Description Framework). The schema is shared under http://cvs.mygrid.org.uk/cgi-bin/viewcvs.cgi/mygrid/miasgrid/rdf-provenance/etc/ontology/. The actual RDF provenance traces are shared under http://www.cs.man.ac.uk/~zhaoj/challenge. Details can be referred in [2].Provenance Queries Matrix
| Teams | Queries | ||||||||||
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | |||
| myGrid team |  | | | | | | | | | ||
Provenance Queries
1. Find the process that led to Atlas X Graphic / everything that caused Atlas X Graphic to be as it is. This should tell us the new brain images from which the averaged atlas was generated, the warping performed etc.
Input: the output data d named as "Atlas X Graphic" in a run r Output: a set of process runs and data that led the d
Note, in answering this query, we constrain the scope of the query within a particular workflow run r in order to avoid presenting too many results, although this can be easily adapted as querying over the whole provenance repository, as shown in the first example. From our understanding, we believe this query requires all the process runs and data that contribute to the creation of d during the run of r, directly or indirectly, should also be returned, rather than only those contribute directly. Thus, this query is realized in two steps:
- getting the identity of d with name as "Atlas X Graphic" in a run r,
Step 1 Get the identity of the output data name as AtlasXGraphic that is generated in the run r:
SELECT ?datalsid WHERE <urn:lsid:www.mygrid.org.uk:experimentinstance:C3WK5J3HNW1> (?datalsid <http://www.mygrid.org.uk/provenance#outputDataHasName> <urn:www.mygrid.org.uk/process#convert1_out_AtlasXGraphic>) USING ns FOR <http://www.mygrid.org.uk/provenance#>In the following query we show how we can find all the d in the whole provenance repository rather than within one run r.
SELECT ?datalsid WHERE (?datalsid <http://www.mygrid.org.uk/provenance#outputDataHasName> <urn:www.mygrid.org.uk/process#convert1_out_AtlasXGraphic>) USING ns FOR <http://www.mygrid.org.uk/provenance#>Result: this returns the d that named as Atlas X Graphic and created in the run urn:lsid:www.mygrid.org.uk:experimentinstance:C3WK5J3HNW1.
Get data urn:lsid:www.mygrid.org.uk:lsdocument:LZ25GL912Y49
Step 2
- Get the collection of data products Di = {d1, d2, dn}, with d being derived from di and the process runs Pi = {p1, p2, pn} that created each data product in Di.
SELECT ?value
WHERE ( <" + sourceIndividual
+ "> <" + myg:dataDerivedFrom + "> ?value ) "
USING ns FOR <http://www.mygrid.org.uk/provenance#>
Result:
This query returns 27 data that d is derived from and 23 process runs that contribute to the creation of d, listed in Figure 2.

Figure 2 The result from provenance query 1
Figure 3 shows how this path can be visualized in the mygrid provenance browser from a process-oriented view. Figure 4 shows how the data path can be visualized as a DAG. This DAG shows how the Atlas X Graphic data, i.e. LZ25GL912Y49, is derived from
- the Atlas X Slice images, i.e. LZ25GL912Y46,
- the average brain image, header and parameter, i.e. LZ25GL912Y44, LZ25GL912Y45, LZ25GL912Y21 and etc.
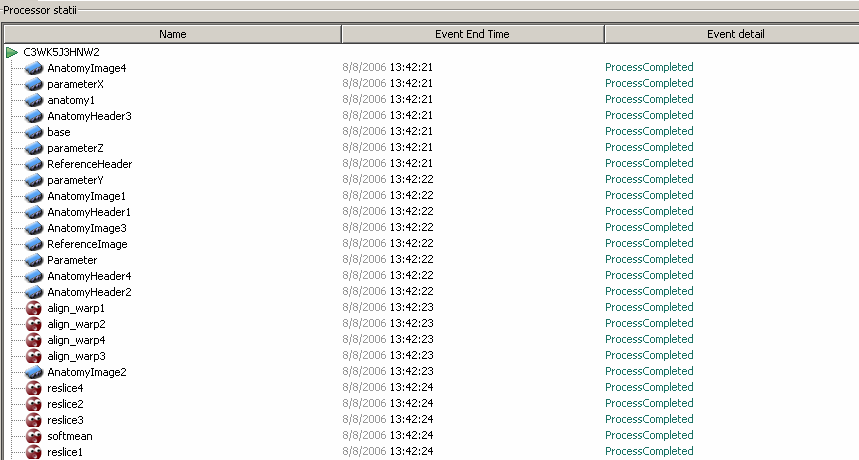
Figure 3 The result in Figure 2 as visualized in the provenance browser
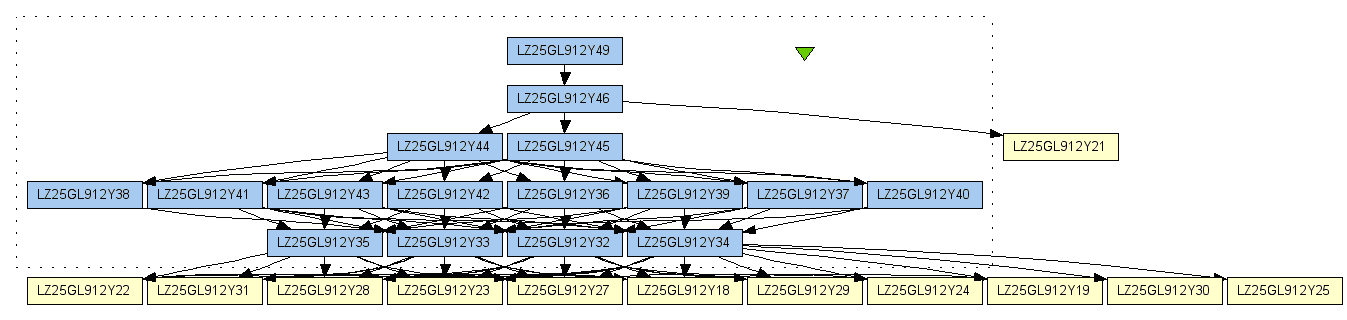
Figure 4 The result in Figure 2 visualized as a DAG
2. Find the process that led to Atlas X Graphic, excluding everything prior to the averaging of images with softmean.
Input: the output d named as AtlasXGraphic and the scope of the query as after softmean Output: a set of process runs {pi} and data {di} that led the d
Similar to the Query1, we first found the identity of d with the name as AtlasXGraphic. In the second step, the result provenance logs are constrained to exclude all the logs about runs prior to softmean. The algorithm is shown in the following: a. Get the collection of data products Di = {d1, d2, dn}, with d being derived from di and the process runs Pi = {p1, p2, pn} that created di in Di. b. if di in Dj is created by running the process softmean, we will not retrieve data that are derived from di. c. If Di contains only data that are created by softmean, the query stops; otherwise go to step d. d. Get the collection of data products Dj, with dj being derived from each di in Di and the process runs Pj that created each data product in Dj. e. query ends. Result: This query returns the 4 data that d is derived from and the 3 process runs that contribute to the creation of d prior to the softmean.
The returned process runs: urn:www.mygrid.org.uk/process_run#1155043506390 urn:www.mygrid.org.uk/process_run#1155043506000 urn:www.mygrid.org.uk/process_run#1155043504343
the returned data: urn:lsid:www.mygrid.org.uk:lsdocument:LZ25GL912Y46 urn:lsid:www.mygrid.org.uk:lsdocument:LZ25GL912Y44 urn:lsid:www.mygrid.org.uk:lsdocument:LZ25GL912Y21 urn:lsid:www.mygrid.org.uk:lsdocument:LZ25GL912Y45
Figure 5 shows how the data path can be visualized as a DAG.
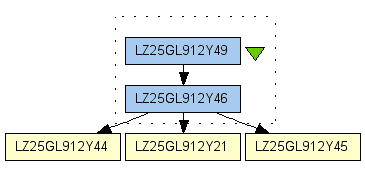
Figure 5. The data view of the result of query 2.
3. Find the Stage 3, 4 and 5 details of the process that led to Atlas X Graphic.
By default, in the mygrid provenance browser users can navigate the complete provenance log of each workflow run. By using query 2, we find the set of process runs that contributed to the creation of Atlas X Graphic, i.e. a subset of the complete provenance log. Figure 6 shows how this subset of logs can be viewed in the mygrid provenance browser, including all the details of these three process runs:- when they were started
- what are the intermediate inputs and outputs of each process run
- the service that was invoked by each process run.
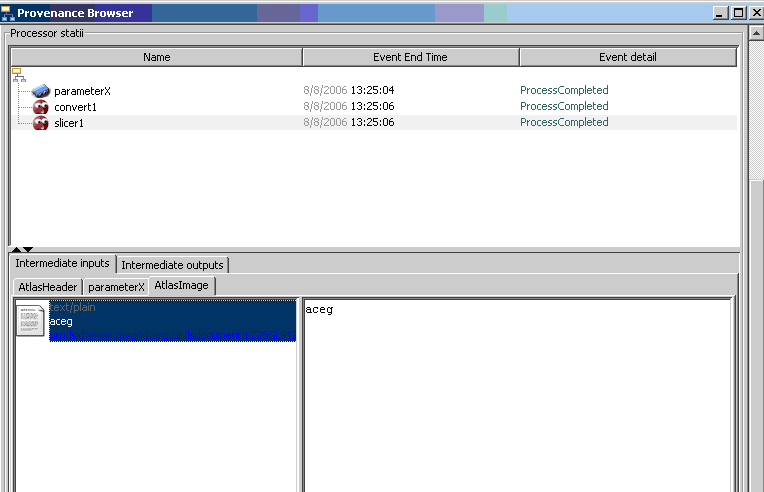
Figure 6. The process view of the returned provenance logs from query 3.
Note, the value of the intermediate data products are retrieved from the data store and we used pseudo values in the workflow runs.
4. Find all invocations of procedure align_warp using a twelfth order nonlinear 1365 parameter model that ran on a Monday.
Input: the name of a process p as align_warp, the property of the parameter as twelfth order, the time of the run as Monday Output: a set of process runs {pi} of the p with each pi satisfying the constraints by the two other inputs of the query, i.e. the parameter property and the date/time of the run.
The property of the parameter was treated as an annotation to the data. This annotation is attached to the workflow definition file using the Taverna knowledge provenance template. This query is realized in two steps. 1) Getting all the runs {ri} that were ran on Monday 2) In each ri, getting all the process runs that invoke the align_warp service with a parameter twelfth order 1) Firstly we get all the runs that were ran on a Monday by the following query: As our provenance logs include the timestamp information about each workflow or process run, we can answer this query by the following query.
SELECT ?p WHERE (?p <http://www.mygrid.org.uk/provenance#startTime> ?time) AND (?time > date) USING ns FOR <http://www.mygrid.org.uk/provenance#> xsd FOR <http://www.w3.org/2001/XMLSchema#>In our example repository, this query returned 2 workflow runs:
urn:lsid:www.mygrid.org.uk:experimentinstance:HXQOVQA2ZI0 urn:lsid:www.mygrid.org.uk:experimentinstance:JF9QILMXB60
2) In the second step we try to find in each of these workflow runs, the invocations of procedure align_warp using a twelfth order nonlinear 1365 parameter model.
SELECT ?p
WHERE <urn:lsid:www.mygrid.org.uk:experimentinstance:HXQOVQA2ZI0>
(?p <http://www.mygrid.org.uk/provenance#runsProcess> ?processname .
?p <http://www.mygrid.org.uk/provenance#processInput> ?inputParameter .
?inputParameter <ont:model> <ontology:twelfthOrder>)
USING ns FOR <http://www.mygrid.org.uk/provenance#>
ont FOR <http://www.mygrid.org.uk/ontology#>
This returns two sets process runs:
- One set invoked in the workflow run urn:lsid:www.mygrid.org.uk:experimentinstance:HXQOVQA2ZI0:
Get runs urn:www.mygrid.org.uk/process_run#1155222243328 Get runs urn:www.mygrid.org.uk/process_run#1155222243578 Get runs urn:www.mygrid.org.uk/process_run#1155222242781 Get runs urn:www.mygrid.org.uk/process_run#1155222243062
- The other set invoked in the workflow run urn:lsid:www.mygrid.org.uk:experimentinstance:JF9QILMXB60
Get runs urn:www.mygrid.org.uk/process_run#1155224291812 Get runs urn:www.mygrid.org.uk/process_run#1155224292453 Get runs urn:www.mygrid.org.uk/process_run#1155224292031 Get runs urn:www.mygrid.org.uk/process_run#1155224292250
5. Find all Atlas Graphic images outputted from workflows where at least one of the input Anatomy Headers had an entry global maximum=4095. The contents of a header file can be extracted as text using the scanheader AIR utility.
Input: a set of data {ind} with the named as Anatomy Headers which has an entry 4095 Output: a set of data {outd} named as Atlas Graphic images which are derived from the {ind}
In order to realize this query, we used the semantic metadata attached to the data products, as we did in the last query. Also to avoid presenting too many results, we choose to search for the target {outd} within a certain workflow run, although this query can be easily extended to query the overall provenance repository, as shown in the query 1. We realize this query in two steps; 1)Getting all the identities for the {ind} 2)Getting all the {outd} which are indirectly derived from {ind} using the deep provenance algorithm. 1) In the first step, we try to find all the {ind}. The query is shown in the following:
SELECT ?data WHERE <urn:lsid:www.mygrid.org.uk:experimentinstance:HXQOVQA2ZI0> (?data <ont:global> ?value) AND (?value eq "ontology:4095") USING ns FOR <http://www.mygrid.org.uk/provenance#> ont FOR <http://www.mygrid.org.uk/ontology#>This returns the data product:
Get data urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN10
This {ind} was produced in the run urn:lsid:www.mygrid.org.uk:experimentinstance:HXQOVQA2ZI0 with the annotation showing that it has a maximum value 4095. 2) In the second, we try to find all the {outd} that are derived from {ind}. As {outd} is not directly derived from {ind}, but from some intermediate data products, including
- The warp parameters
- The resliced images
- The averaged brain image
- The slice images from the slicer.
urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN33 urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN32 urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN31
This can be simply verified by the little data derivation path shown in Figure 7. This figure shows which three Atlas Graphic images (CIEIR0DODN33, CIEIR0DODN32, CIEIR0DODN31) are derived from the header data CIEIR0DODN10 and how they are derived from CIEIR0DODN10 indirectly during a workflow run.
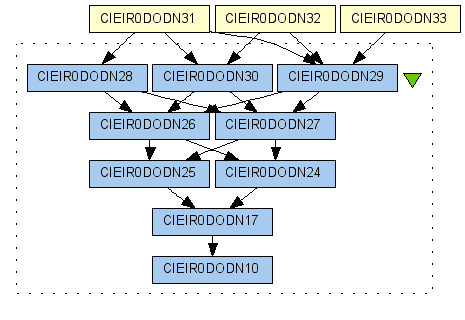
Figure 7.The data derivation path for the query 5.
6. Find all output averaged images of softmean (average) procedures, where the warped images taken as input were align_warped using a twelfth order nonlinear 1365 parameter model, i.e. "where softmean was preceded in the workflow, directly or indirectly, by an align_warp procedure with argument -m 12."
Input: a set of data {ind} that are input of align warp with the parameter -m 12 Output: a set of data {outd} that are output of softmean that are derived from {ind}
This query is similar to query 5. The target point for the deep provenance algorithm is changed to output of softmean. Thus two steps are performed to answer this query. In the first step, we look for the identities of {ind} produced in a workflow run:
SELECT ?data WHERE <urn:lsid:www.mygrid.org.uk:experimentinstance:HXQOVQA2ZI0> (?p <http://www.mygrid.org.uk/provenance#processInput> ?data . ?data <ont:model> ?value) AND (?value eq "ontology:twelfthOrder") USING ns FOR <http://www.mygrid.org.uk/provenance#> ont FOR <http://www.mygrid.org.uk/ontology#>And this returned one input to the runs of a align_warp service, which used the argument twelfthOrder:
Get data urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN11
In the second step, we use the same deep provenance query to find the {outd} from softmean that is directly from {ind}. This returns two data products as the following:
urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN26 urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN27
This shows that this parameter contributed to the production of 2 outputs from the softmean. This can be verified by the data derivation path in Figure 8, where the two outputs from softmean, i.e. (CIEIR0DODN26 and CIEIR0DODN27), are derived from the parameter input to the align_warp, i.e. (CIEIR0DODN11).
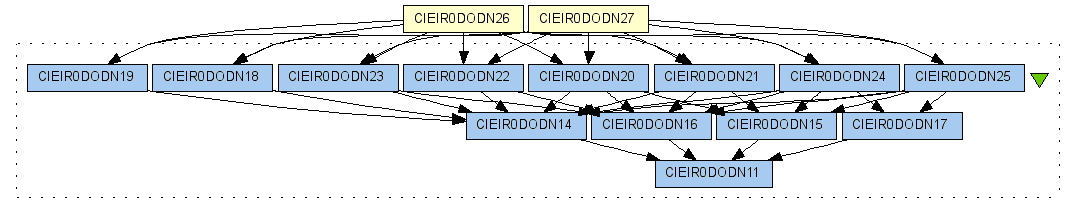
Figure 8. The data derivation path for the query 6.
7. A user has run the workflow twice, in the second instance replacing each procedures (convert) in the final stage with two procedures: pgmtoppm, then pnmtojpeg. Find the differences between the two workflow runs. The exact level of detail in the difference that is detected by a system is up to each participant.
In mygrid, this comparison can be done in three levels:- at the workflow design level
- at the process view of provenance
- at the data view of provenance
difference urn:www.mygrid.org.uk/process#convert1 difference urn:www.mygrid.org.uk/process#convert3 difference urn:www.mygrid.org.uk/process#convert2 difference urn:www.mygrid.org.uk/process#pnmtojpeg1 difference urn:www.mygrid.org.uk/process#pnmtojpeg3 difference urn:www.mygrid.org.uk/process#pgmtoppm2 difference urn:www.mygrid.org.uk/process#pnmtojpeg2 difference urn:www.mygrid.org.uk/process#pgmtoppm3 difference urn:www.mygrid.org.uk/process#pgmtoppm1
At the process view of provenance: We can find out different levels of differences between these two runs, including:
- the different execution time for each workflow/process run
- the process runs that invoked different services
Get process runs urn:www.mygrid.org.uk/process_run#1155132483171 Get process runs urn:www.mygrid.org.uk/process_run#1155132483312 Get process runs urn:www.mygrid.org.uk/process_run#1155132482984 Get process runs urn:www.mygrid.org.uk/process_run#1155132483250 Get process runs urn:www.mygrid.org.uk/process_run#1155132483093 Get process runs urn:www.mygrid.org.uk/process_run#1155132482921
At the data view of provenance: We can find out the different data products that were produced in each run. As in mygrid, each data product is given a unique identity within each run. Two data products with the same data values but computed by the same process in different runs, i.e. equivalent data products, are given different identities. In the provenance logs, as only the data identities but not the data values are recorded, the data identities for the equivalent data products have to be processed before comparing the two logs. This work has been published in our paper[2]. After the normalization process, we succeeded in finding the following different data products were produced by comparing one run with another:
urn:lsid:www.mygrid.org.uk:lsdocument:0XU3I4PS2Q34 urn:www.mygrid.org.uk/workflow#pnmtojpeg1_out_AtlasXGraphic urn:lsid:www.mygrid.org.uk:lsdocument:0XU3I4PS2Q36 urn:www.mygrid.org.uk/workflow#pnmtojpeg3_out_AtlasZGraphic urn:lsid:www.mygrid.org.uk:lsdocument:0XU3I4PS2Q32 urn:www.mygrid.org.uk/process#pgmtoppm2_out_PpmAtlasYGraphic urn:lsid:www.mygrid.org.uk:lsdocument:0XU3I4PS2Q35 urn:www.mygrid.org.uk/workflow#pnmtojpeg2_out_AtlasYGraphic urn:lsid:www.mygrid.org.uk:lsdocument:0XU3I4PS2Q33 urn:www.mygrid.org.uk/process#pgmtoppm3_out_PpmAtlasZGraphic urn:lsid:www.mygrid.org.uk:lsdocument:0XU3I4PS2Q31 urn:www.mygrid.org.uk/process#pgmtoppm1_out_PpmAtlasXGraphic
8. A user has annotated some anatomy images with a key-value pair center=UChicago. Find the outputs of align_warp where the inputs are annotated with center=UChicago.
Input: the semantic annotation center=UChicago Output: a set of data {outd} that are directly derived from data {ind} annotated with the semanticMarp.
This query is realized in two steps: 1). Getting the {ind} that are annotated with center=UChicago in a workflow run r; 2). Getting the {outd} that are derived from {ind} in this run r. 1) The query of the first step is shown as the following:
SELECT ?data WHERE <urn:lsid:www.mygrid.org.uk:experimentinstance:HXQOVQA2ZI0> (?data <ont:center> ?value) AND (?value eq "ontology:UChicago") USING ns FOR <http://www.mygrid.org.uk/provenance#> ont FOR <http://www.mygrid.org.uk/ontology#>This returns:
Get data urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN5
This data was created in the workflow run urn:lsid:www.mygrid.org.uk:experimentinstance:HXQOVQA2ZI0 and annotated with center=UChicago. Without scoping in which workflow we query, the query will be like:
SELECT ?data WHERE (?data <ont:center> ?value) AND (?value eq "ontology:UChicago") USING ns FOR <http://www.mygrid.org.uk/provenance#> ont FOR <http://www.mygrid.org.uk/ontology#>And this returns more than one target data as each of it was produced in different workflow runs:
Get data urn:lsid:www.mygrid.org.uk:lsdocument:N0OUDYG6JS11 Get data urn:lsid:www.mygrid.org.uk:lsdocument:WPVNL86SO56 Get data urn:lsid:www.mygrid.org.uk:lsdocument:JDD53ECRD65 Get data urn:lsid:www.mygrid.org.uk:lsdocument:1JBOYN02LN8 Get data urn:lsid:www.mygrid.org.uk:lsdocument:0XU3I4PS2Q7 Get data urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN5 Get data urn:lsid:www.mygrid.org.uk:lsdocument:0O00XFCTI15
2) In the second step, we try to find the {outd} that are derived from the {ind} in the run r.
Get data urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN17
This returns one data that is output from align_warp, whose input was annotated with center=UChicago.
9. A user has annotated some atlas graphics with key-value pair where the key is studyModality. Find all the graphical atlas sets that have metadata annotation studyModality with values speech, visual or audio, and return all other annotations to these files.
Input: the semantic annotation studyModality = speech Output: a set of data {outd} that are annotated with the semanticMarp and the set of semantic annotations about {outd}.
The first part of the query is the same as query 8:
SELECT ?data WHERE <urn:lsid:www.mygrid.org.uk:experimentinstance:HXQOVQA2ZI0> (?data <ont:studyModality> ?value) AND (?value eq "ontology:speech") USING ns FOR <http://www.mygrid.org.uk/provenance#> ont FOR <http://www.mygrid.org.uk/ontology#>This returns:
Get data urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN32
In the second part of the query, as all the semantic annotations are sub properties of the property userDefinedPredicate in our provenance ontology, in order to find other semantic annotations attached to a data product, we only need to retrieve all the user defined predicates and all the RDF typing information about this data product. The result returns the following other semantic annotations about this data product CIEIR0DODN32, which tells that CIEIR0DODN32 is a type of Atlas Graphic, an atomic data object and a data object.
urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN32 rdf:type ontology:AtlasGraphic urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN32 rdf:type http://www.mygrid.org.uk/provenance#DataObject urn:lsid:www.mygrid.org.uk:lsdocument:CIEIR0DODN32 rdf:type http://www.mygrid.org.uk/provenance#AtomicData
Suggested Wokflow Variants
As shown by the example workflow of this provenance challenge, the same service was invoked more than once in one workflow run, e.g. the align warp, reslice, slicer and convert service. In Taverna, in order to realize this abstract workflow, we had created three instances of each such service at each stage. This works fine when only three different inputs were processed in a workflow, as in the example. But in reality there are many chances that many more, e.g. thousands of inputs were processed by the same service in one workflow run, sometimes with different parameters. Therefore, we propose extending the example workflow with iterations and nested workflows, as already supported in the Taverna system:- Figure 9 shows the challenge workflow was revised as a workflow using implicit iterations. The inputs to the workflow including AnatomyImage, AnatomyHeader and SliceParameter will be a list data object. The services align_warp, reslice, slicer and convert will be iterated three times during the run. Our provenance model allows us to collect all the information about the iteration, including
- how many times a service was iterated,
- what data was used or produced in each iteration.
- Figure 10 shows the challenge workflow was revised as a workflow using a nested workflow for the image slicing and converting. By using nested workflows, scientists managed to have modularized workflows and better chances of workflow reuse. Our provenance model also allows us to collect all the provenance information about the nested workflow runs, including
- when a nested workflow was started or finished,
- what data were used or produced by the nested workflow and the services invoked in this nested workflow,
- was the nested workflow iterated or how many times it has been iterated.
- the relationship between the parent workflow and the nested workflow, etc.
- Figure 11 shows how a user interaction service can be used in this challenge workflow in order to support scientists to checkpoint and verify some intermediate data products before continuting the workflow run.
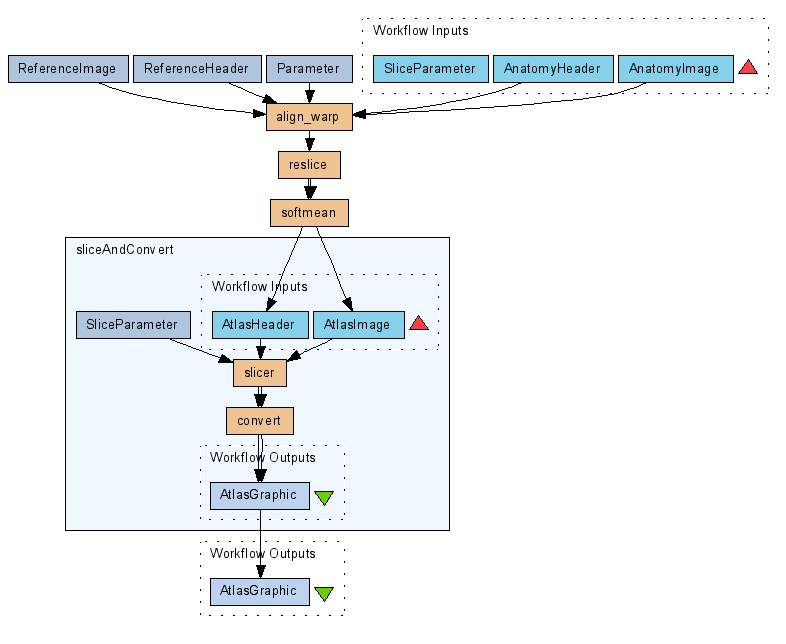
Figure 9. Adopting implicit iterations.
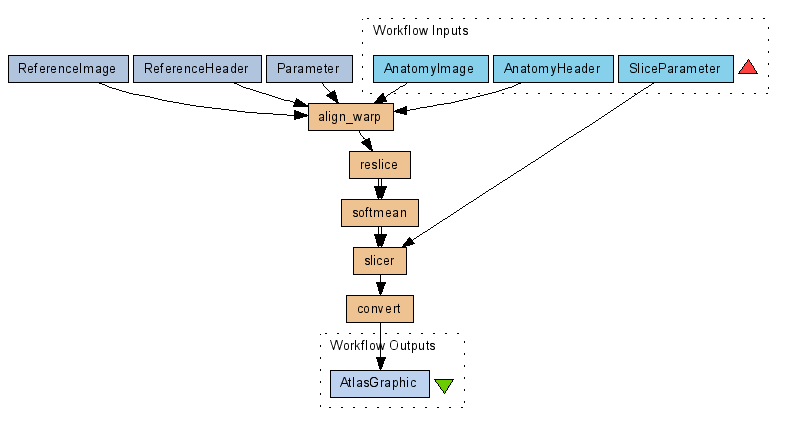
Figure 10. Using a nested workflow.
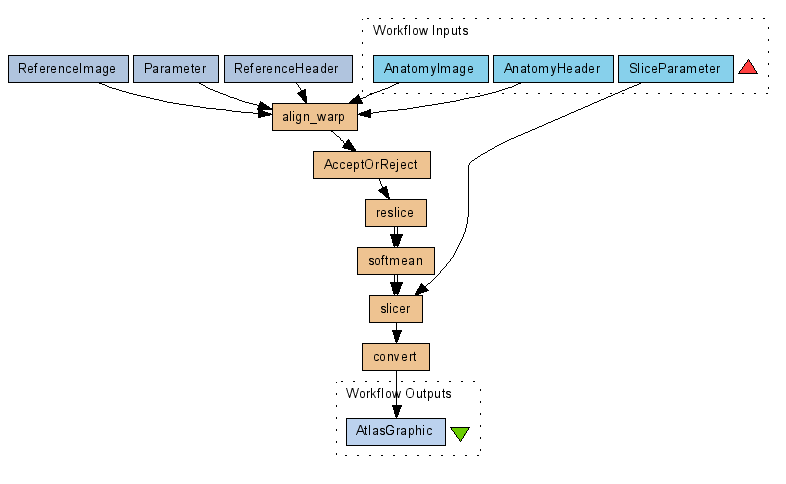
=Figure 11. Using interaction service. =
Suggested Queries
Categorisation of queries
Generally speaking, our provenance queries can be categorized into four levels:- queries to support the provenance browser
- semantic queries
- integration queries
- pre-canned queries to support provenance usage scenarios.
Live systems
- Taverna: http://taverna.sourceforge.net
- Provenance plugin and browser: bundled with the Taverna release 1.4.
- Provenance ontology: http://cvs.mygrid.org.uk/cgi-bin/viewcvs.cgi/mygrid/miasgrid/rdf-provenance/etc/ontology/
Further Comments
Conclusions
-- JunZhao - 29 Aug 2006to top
Edit | Attach image or document | Printable version | Raw text | More topic actions
Revisions: | r1.8 | > | r1.7 | > | r1.6 | Total page history | Backlinks
Revisions: | r1.8 | > | r1.7 | > | r1.6 | Total page history | Backlinks