Challenge
Start of topic | Skip to actions
Second Provenance Challenge
Motivation
The first provenance challenge was established following the IPAW 2006 workshop, where a range of papers were presented that described provenance models and systems. The challenge was proposed as a means for the disparate groups to gain a better understanding of the similarities, differences, core concepts and common issues across systems. The challenge consisted of running a workflow for an fMRI application and answering a set of queries over the provenance derived. The participants all executed this same workflow and performed the same set of queries over the data collected regarding the execution. At the conclusion of the challenge, the participants met and discussed their results, the commonality of the problem being a point around which comparison could take place. While the first challenge had a large number of participants and led to valuable discussion about the aspects of provenance which were fundamental to all approaches, the queries and their expected results were weakly specified, and so interpreted differently by different groups. There was, therefore, no systematic way to compare capabilities of systems, including representations of provenance data. It was decided that a second challenge, based on the first, was desirable. With the first challenge showing that there are multiple levels of granularity/types of provenance that may be relevant at different times or in different parts of a process, understanding interoperability becomes a key issue, and so this will be the focus of second challenge. One way in which the interoperability of the approaches could be tested would be to compose the workflow execution systems, each system executing a part of the workflow, and run provenance queries over the results. However, this would primarily present a challenge to workflow systems rather than approaches to provenance: the scientific value of provenance will come from tracking provenance across workflow runs, through manual processes, and across workflow/provenance systems. Instead, we propose that teams share provenance data produced by their different systems, and then perform provenance queries over compositions of data from other teams, as if it had been produced by their own system. Through this approach, the second provenance challenge should encourage systematic conversions of data between systems, and so a reliable basis of comparison. Specifically, we hope to achieve the following goals.- Understand where data in one model is translatable to or has no parallel in another model.
- Understand how the provenance of data can be traced across multiple systems, so adding value to all those systems.
Timetable
The timeline for the second provenance challenge is as follows:- November 2006 Draft of challenge presented for discussion
- Start of December 2006 Challenge starts
- 20th of February 2007 First phase of challenge ends
- 26th of June 2007 Challenge ends, workshop to discuss results
Communicable Data Model
The first phase of the challenge is to make available provenance data/process documentation for adequate workflow runs to answer the provenance queries. As the focus of the challenge is to share and combine data models, we need to make it easy for other teams to parse the data. Therefore, the data should be exported in a well documented format, and a reference given to a free parser for that format. For consistency and availability of parsers, we strongly encourage (but do not require) teams to export their data in XML. The schema should be provided and adequately described for others to use, either in the schema document, on the TWiki or in a referenced document. The second challenge is based on the same workflow as the first. However, it is now divided into three parts:- Part 1: align_warp and reslice (stages 1 and 2)
- Part 2: softmean (stage 3)
- Part 3: slicer and convert (stages 4 and 5)
- Documentation of the three parts of one run of the workflow as shown in the Workflow Parts section below.
- Documentation of the three parts of one run of the workflow in the adaptation specified by Provenance Query 7, i.e. replacing the single
convertprocedure with two procedures,pgmtoppmthenpnmtojpeg, in workflow Part 3. - The following annotations:
- Anatomy Image 1, as used in the first workflow run, is annotated with key-value pair center=UChicago.
- Anatomy Image 2, as used in the first workflow run, is annotated with key-value pairs center=southampton and studyModality=speech.
Cross-Model Provenance Query
The second phase of the challenge is for each team to use their approach to combine provenance data produced in the first phase by multiple other teams and use their approach to query over it. Each team should download data for each of the three workflow parts, each part from a different originating team. They must then perform the queries from the first provenance challenge over the combined three parts, as if they had captured the provenance data themselves. This is likely to involve, for most teams, a first step of translating the downloaded data into their own models. The queries are listed in the Provenance Queries section below. Teams should perform queries over as many combinations as they feel is adequate for fulfilling the challenge goals above, but must query over at least one other team's data to have completed the challenge. Additional credit goes to teams whose data has been successfully imported and queried over by others!Benchmarks for Provenance Systems
We aim to build a repository with different scenarios and queries, where each scenario/query combination exercises different features of provenance systems. The goal would be to classify the different systems with respect to their ability to handle the different scenarios. This exercise will be informed by the results of the second provenance challenge, where significant differences in approach should become apparent through attempting to translate data models. will be discussed at the second challenge workshop and we hope it will continue from there.Results
Teams should report the following results for the challenge:- Which combinations of models they have managed to perform the provenance query over
- Details regarding how data models were translated (or otherwise used to answer the query following the team's approach)
- Any data which was absent from a downloaded model, and whether this affected the possibility of translation or successful provenance query
- Any data which was excluded in translation from a downloaded model because it was extraneous
- Benchmark queries and results of applying their own suggested benchmarks to their own system
Workflow Parts
This challenge is based on the same workflow definition as in the first challenge. However, the workflow definition is now split into three parts, depicted graphically here. As shown below, the workflow is comprised of procedures exchanging data. We do not want to restrict the execution environment for workflow runs, as the challenge is about provenance, and so only define only the essentials of the workflow: the roles of data in the workflow, types of procedure performed and where the output of one procedure becomes input for another. We do not otherwise prescribe how workflows are instantiated or run. The details of the workflow definition are given on the first provenance challenge page, as are pre-computed data for each of the items in the workflow for those that wish to simulate their workflow runs. Click on workflow images for high resolution versions.Part 1
This part is the reslicing of images to fit one reference image. It includes two stages: align_warp and reslice.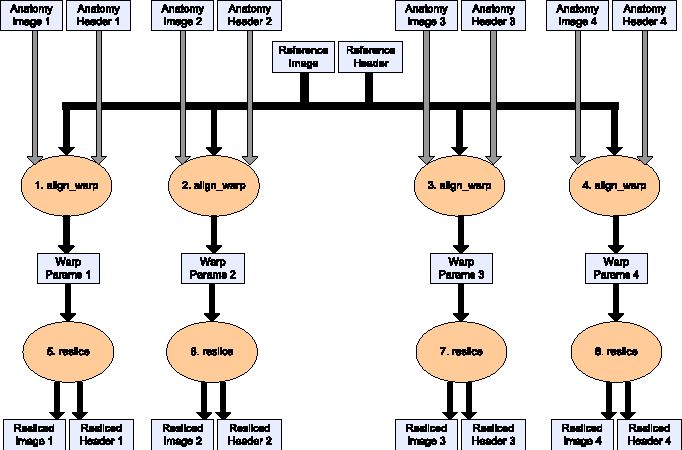
Part 2
This part is the averaging of brain images into one. It includes one stage: softmean.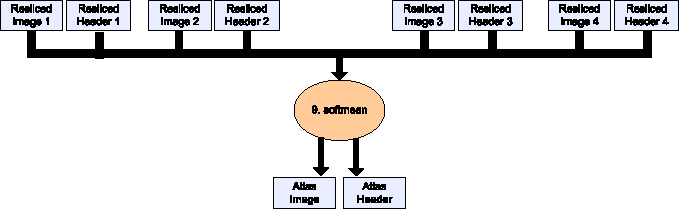
Part 3
This part is the conversion of the averaged image into three graphics files showing slices of that brain. It includes two stages: slicer and convert.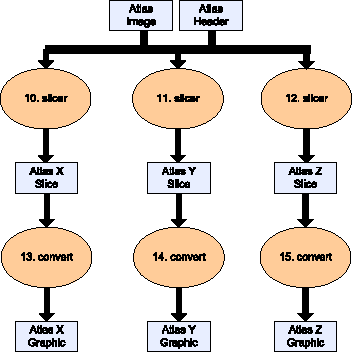
Provenance Queries
These are the same queries as in the first challenge, but more tightly specified to remove ambiguities.- Find the process that led to Atlas X Graphic / everything that caused Atlas X Graphic to be as it is. This should tell us the new brain images from which the averaged atlas was generated, the warping performed etc.
- Find the process that led to Atlas X Graphic, excluding everything prior to softmean outputting the Atlas Image, i.e. the inputs, processing and outputs of align_warp and reslice, and the inputs and processing of softmean will be excluded.
- Find the Stage 3, 4 and 5 details of the process that led to Atlas X Graphic.
- Find all invocations of procedure align_warp that have ever occurred in the system using a twelfth order nonlinear 1365 parameter model (see model menu describing possible values of parameter "-m 12" of align_warp) that ran on a Monday.
- Find all Atlas Graphic images outputted from workflows where at least one of the input Anatomy Headers had an entry global maximum=4095. The contents of a header file can be extracted as text using the scanheader AIR utility.
- Find all images ever output from softmean where the warped images taken as input were align_warped using a twelfth order nonlinear 1365 parameter model, i.e. "where softmean was preceded in the workflow, directly or indirectly, by an align_warp procedure with argument -m 12."
- A user has run the workflow twice on the same input files, in the second instance replacing each convert procedure in the final stage with two procedures: pgmtoppm, then pnmtojpeg. Find the differences between the two workflow runs. The exact level of detail in the difference that is detected by a system is up to each participant.
- A user has annotated some anatomy images with a key-value pair center=UChicago. Find the outputs of align_warp where the inputs are annotated with center=UChicago.
- A user has annotated some atlas graphics with key-value pair where the key is studyModality. Find all the graphical atlas sets that have metadata annotation studyModality with values speech, visual or audio, and return all other annotations to these files.
to top
| I | Attachment  | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| | First.png | manage | 15.2 K | 03 Oct 2006 - 10:41 | SimonMiles | First part of workflow |
| | Second.png | manage | 6.6 K | 03 Oct 2006 - 10:41 | SimonMiles | Second part of workflow |
| | Third.png | manage | 8.3 K | 03 Oct 2006 - 10:41 | SimonMiles | Third part of workflow |
| | First.pdf | manage | 92.0 K | 03 Oct 2006 - 10:47 | SimonMiles | First part of workflow (hi-res) |
| | Second.pdf | manage | 36.2 K | 03 Oct 2006 - 10:47 | SimonMiles | Second part of workflow (hi-res) |
| | Third.pdf | manage | 33.6 K | 03 Oct 2006 - 10:47 | SimonMiles | Third part of workflow (hi-res) |
{kind=link}
{kind=link}
{kind=link}
Edit | Attach image or document | Printable version | Raw text | More topic actions
Revisions: | r1.16 | > | r1.15 | > | r1.14 | Total page history | Backlinks
Revisions: | r1.16 | > | r1.15 | > | r1.14 | Total page history | Backlinks